Métodos para la clasificación
En esta página se describirán los métodos y técnicas utilizados para la clasificación de las colonias en sus respectivas especies.
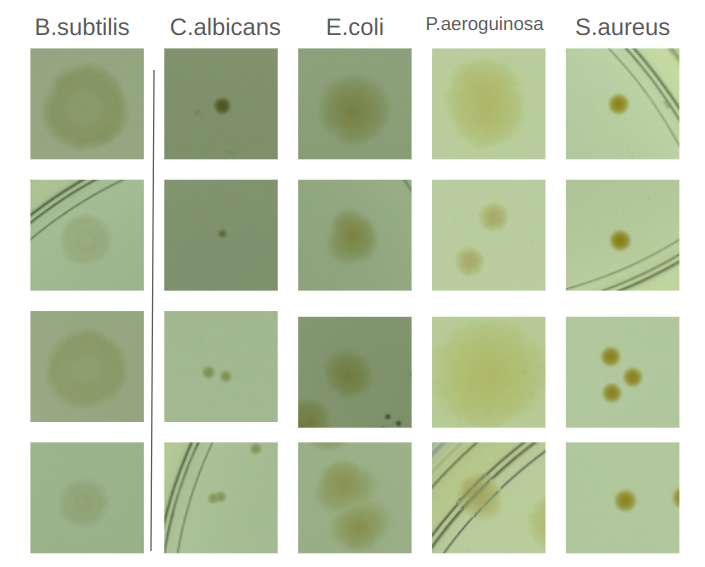
El principal desafío a la hora de poder separar las colonias por especie es encontrar las features o características que permitan una correcta separación. En la Figura 1 se puede observar la gran variabilidad que hay en la forma y el color dentro de una misma clase de colonia, es por esta razón que la elección de las características a utilizar en el clasificador no es una tarea sencilla.
Características elegidas
- El promedio y la desviación estándar de cada canal de la imagen.
- El promedio y la desviación estándar de cada canal para el área reconocida como colonia.
- El promedio y la desviación estándar de cada canal en el espacio de color HSB, HUE, saturación y brillo.
- El promedio y la desviación estándar de cada canal en el espacio de color LAB, iluminación, eje x y eje y.
- Descriptores de la matriz de co-ocurrencia, el contraste, la disimilaridad, homogeneidad, energía y correlación.
Modelos utilizados
RandomForest
El modelo Random Forest es un método de machine learning que combina múltiples árboles de decisión para crear un modelo más robusto y preciso 1. Esta técnica utiliza el bagging (esta es una técnica usada para reducir la varianza de las predicciones a través de la combinación de los resultados de varios clasificadores) para generar subconjuntos aleatorios de datos y características, creando diversos árboles que "votan" para producir una predicción final. Este modelo es eficaz para manejar datos de alta dimensionalidad (la cantidad de características que obtengo para cada colonia hace que sea de alta dimensionalidad) y reducir el sobreajuste.
SVM
Las Máquinas de Vectores de Soporte (SVM) son un potente algoritmo de aprendizaje supervisado utilizado tanto para clasificación como para regresión 2. SVM busca encontrar un hiperplano óptimo que separe las clases en un espacio de características de alta dimensión, maximizando el margen entre las clases. Una característica de este modelo es la capacidad para manejar relaciones no lineales mediante el uso de funciones kernel, que transforman los datos a un espacio de mayor dimensión.
-
L Breiman. Random forests. Machine Learning, 45:5–32, 10 2001. doi:10.1023/A:1010950718922. ↩
-
Corinna Cortes and Vladimir Vapnik. Support-vector networks. Chem. Biol. Drug Des., 297:273–297, 01 2009. doi:10.1007/%2FBF00994018. ↩